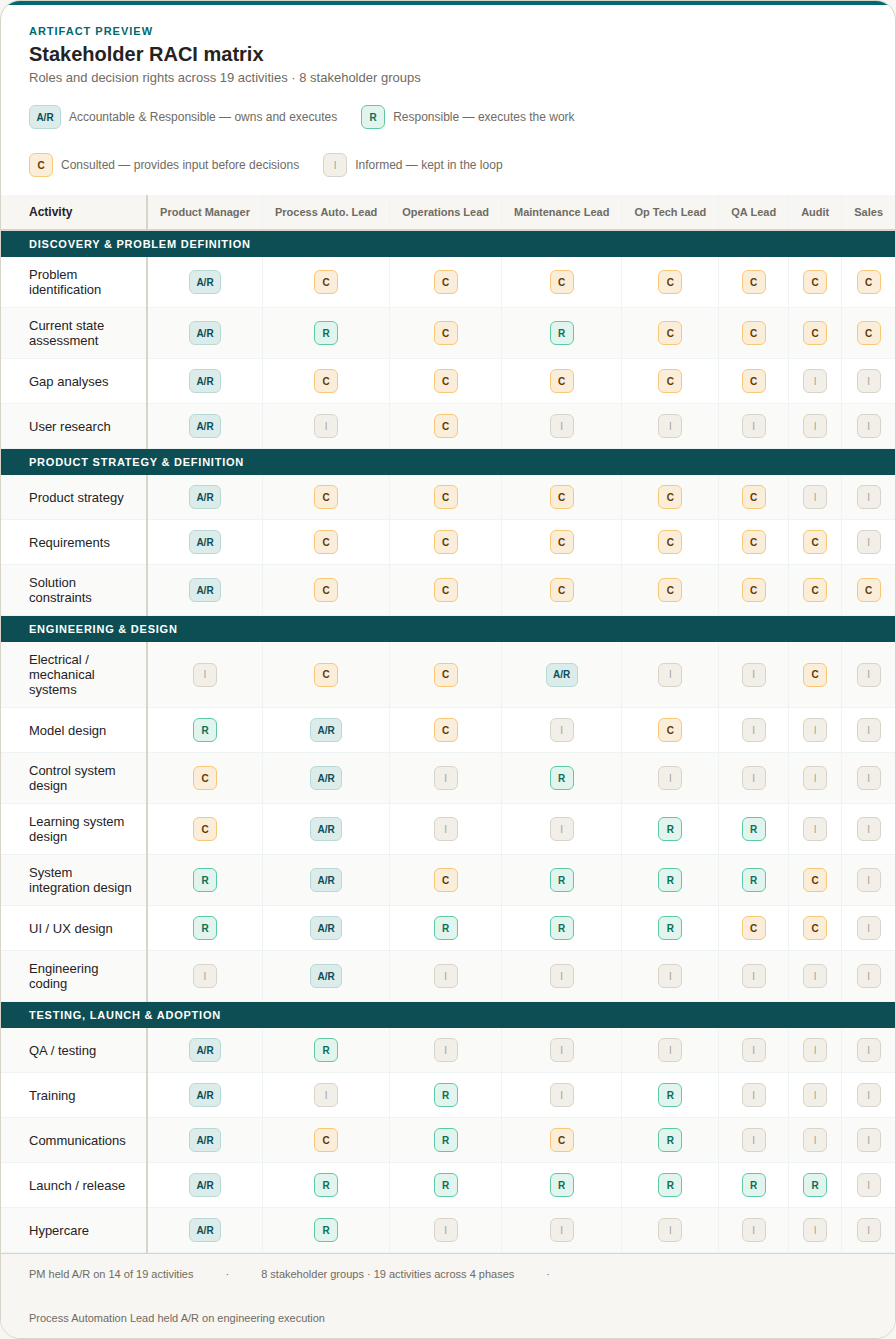
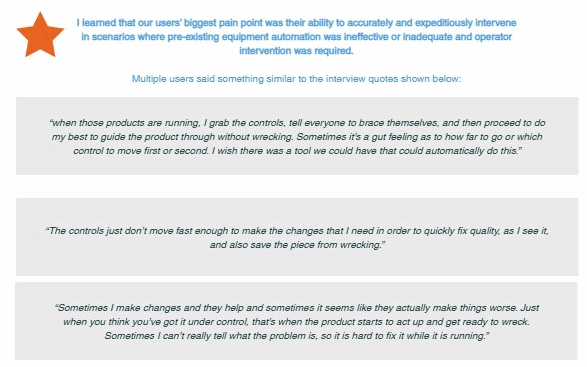
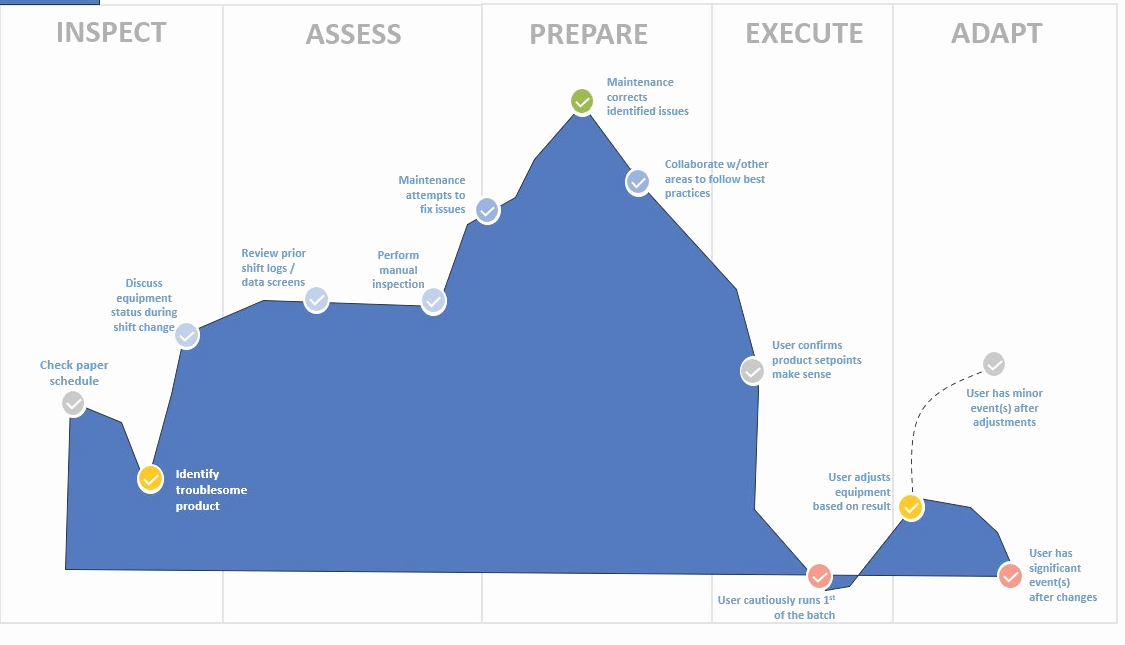
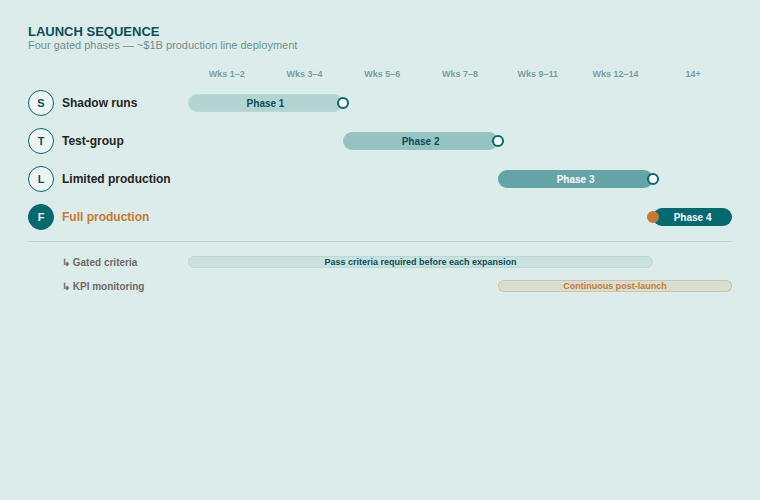
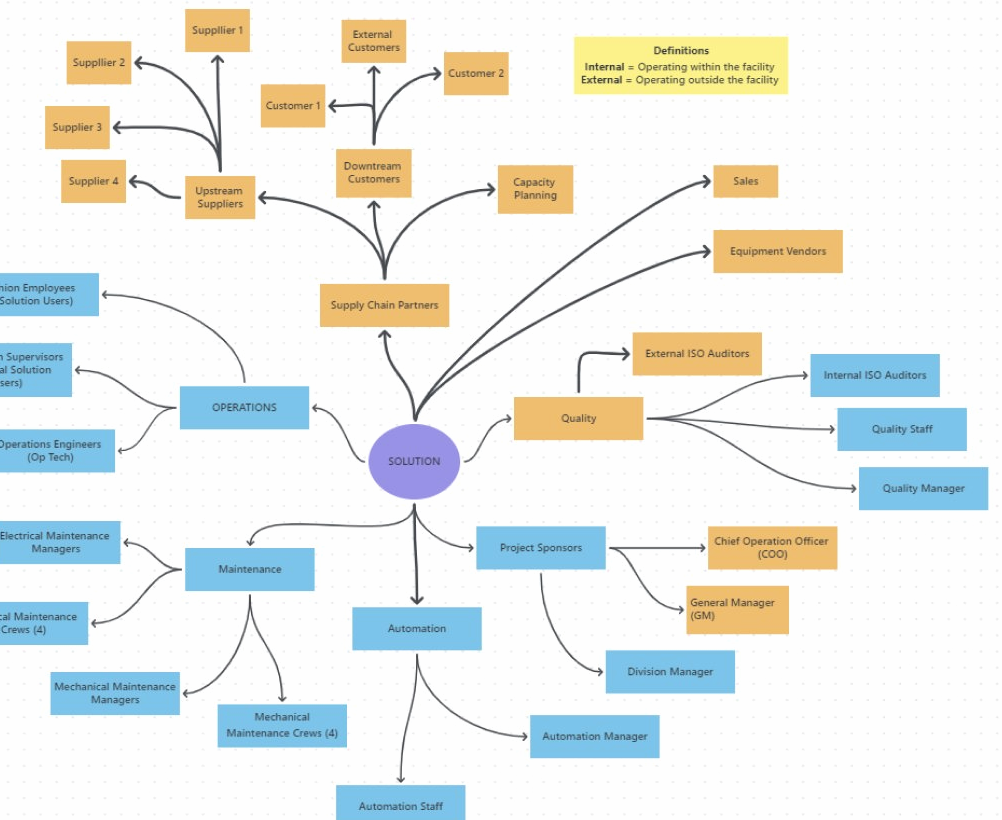
Every product decision in this phase was traceable back to something a user said or a number confirmed.
Product definition on this program moved through four deliberate steps: problem statements → constraint-free ideation → solution alignment → prioritized MVP scope. Each step was designed to do specific work — not just sequence activities, but prevent the team from solution-jumping before the problem was sufficiently understood, and prevent groupthink from narrowing the solution space too early.
1
Problem statements — translating VoC into structured scope
Using the personas as guides, I generated persona-centered problem statements that translated VoC themes into actionable scope. Each statement mapped a specific user need to a solution requirement, giving the team a concrete target rather than an abstract theme. Critically, I used an anonymous idea collection method during this phase to reduce bias — ensuring that the diversity of experience and seniority in the room didn't cause quieter voices to defer to louder ones. The feedback was documented digitally and synthesized into value statements that every stakeholder could see themselves in.
The goal wasn't just to document problems — it was to surface the maximum number of synergies a single product could address. The more jobs-to-be-done one solution could handle, the broader the adoption case and the stronger the business justification.

Problem statements
Persona-centered statements mapped to solution needs — from yield loss and safety exposure to manual intervention burden. Each row represents a traceable line from user insight to product requirement.
2
Constraint-free ideation — expand before you narrow
Before reintroducing any constraints, I facilitated ideation sessions designed to generate a large number of potential solutions without filtering. No idea was out of bounds — no technical constraints, no budgetary limits, no HR, production schedule, time-to-market, management optics, or workforce culture constraints. This was intentional: constraints introduced too early cause teams to anchor on what's feasible rather than what's valuable.
I prompted participants with questions designed to surface latent needs: what they'd want their systems to do differently, what upstream operations could do better, what information they'd need to make better decisions, and what good would actually look like if nothing was holding them back. Having the problem statements visible during this session accelerated alignment — it's easier to imagine solutions when you're looking at a structured problem than when you're working from memory.
3
Solution alignment — reintroduce constraints, converge on direction
Once the ideation space was fully explored, I reintroduced constraints to move the group toward a definable MVP. The team collectively aligned on an in-house automation product that would integrate a new control system with a novel closed-feedback loop and enhanced model learning capabilities. This was not an off-the-shelf solution — it required building something that didn't exist, calibrated specifically to the facility's equipment, product mix, and operator reality.
At its technical core, the product combined machine learning with traditional control theory — specifically, a weighted predictive model that continuously updated based on feedback from its own outputs over time. Rather than relying solely on pre-programmed logic or static setpoints, the system learned from what it had previously recommended and whether those recommendations led to better or worse outcomes. The specific implementation — how the model was structured, how learning was weighted across a complex product mix, and how control decisions were derived — is proprietary. What can be said is that the architecture was designed to get smarter with use, not just operate at a fixed level of accuracy.
For the operators, this translated to a system that provided real-time corrective guidance — reducing the cognitive burden of manual intervention and giving both junior and senior operators a reliable second opinion during the moments that mattered most.
To define what the MVP would actually need to be and do, I scheduled requirements elicitation sessions across stakeholder groups — using formal interviews, informal conversations, and independent data gathering in parallel. The sessions were structured around seven core questions: what the solution would need to look like, how it should work, what it should never do, how end-users would use it, why non-functional stakeholders should care, which users wanted design input, and critically — if it worked as intended, would the end-user actually use it, and why or why not?
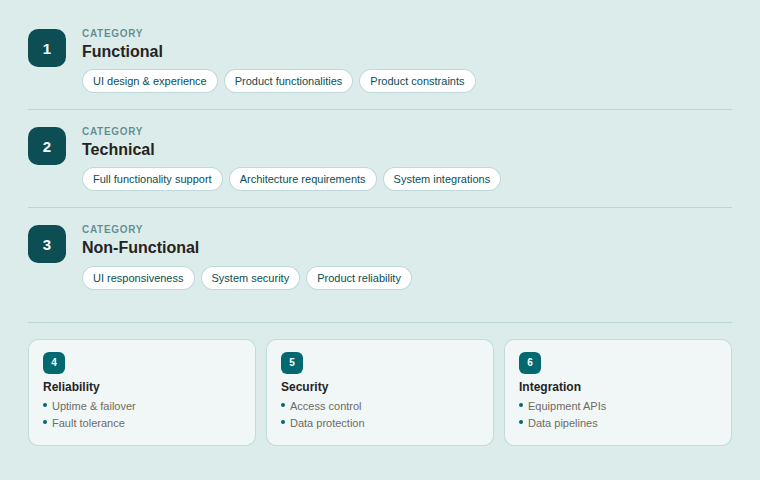
Requirements hierarchy
Six requirement categories built from elicitation sessions: Functional, Technical, Non-Functional, Reliability, Security, and Integration. Each requirement traceable to a stakeholder input or a constraint identified during solutioning.
4
RICE prioritization — a fair, transparent framework for hard tradeoffs
With a full feature list assembled, the next challenge was prioritization — and in a room with strong opinions and competing stakeholder interests, intuition-based prioritization creates friction. I used the RICE matrix to score each candidate feature against reach, impact, confidence, and effort. The transparency of the method did as much work as the scores themselves: when senior stakeholders could see exactly why one feature outranked another, alignment came faster and held longer.

RICE prioritization matrix
Four feature candidates scored against reach, impact, confidence, and effort. Closed Loop Real-Time Correction scored 94 — nearly double the next candidate — and became the undisputed anchor of the MVP. The method gave stakeholders a shared, defensible basis for every scope decision that followed.